
三个程序员奋战三天重写推理堆栈,Grok-2 mini直接提速两倍,马斯克亲发贺电
一直在用 Grok-2 的用户可能察觉到,这两天,它好像变快了:

上周,xAI 发布了 Grok-2 聊天机器人,并在 X 平台上以每月 8 美元的价格提供服务。
用户的感觉也不是错觉,Grok-2 的两个版本 Grok-2 和 Grok-2 mini(后者功能更弱但速度更快),确实都提高了分析信息和输出回复的速度。
xAI 的开发人员 Igor Babuschkin 发布了一条动态,揭示了这次提速背后的原因:

正如这条动态所说,他和 xAI 的另外两名开发人员 Lianmin Zheng 和 Saeed Maleki 奋战了三天,用 SGLang 重写了推理技术栈。

这次奋战的结果很理想:在评价人工智能模型性能的第三方 Lmsys Chatbot Arena 排行榜更新中,Grok-2 主模型在 6686 次投票中获得了 1293 分的成绩。这使得 Grok-2 成为世界上最强人工智能模型中的第二名,与谷歌的 Gemini-1.5 Pro 模型并列,仅次于 OpenAI 的最新版本 ChatGPT-4o,且超越了 GPT-4o(2024 年 5 月)。
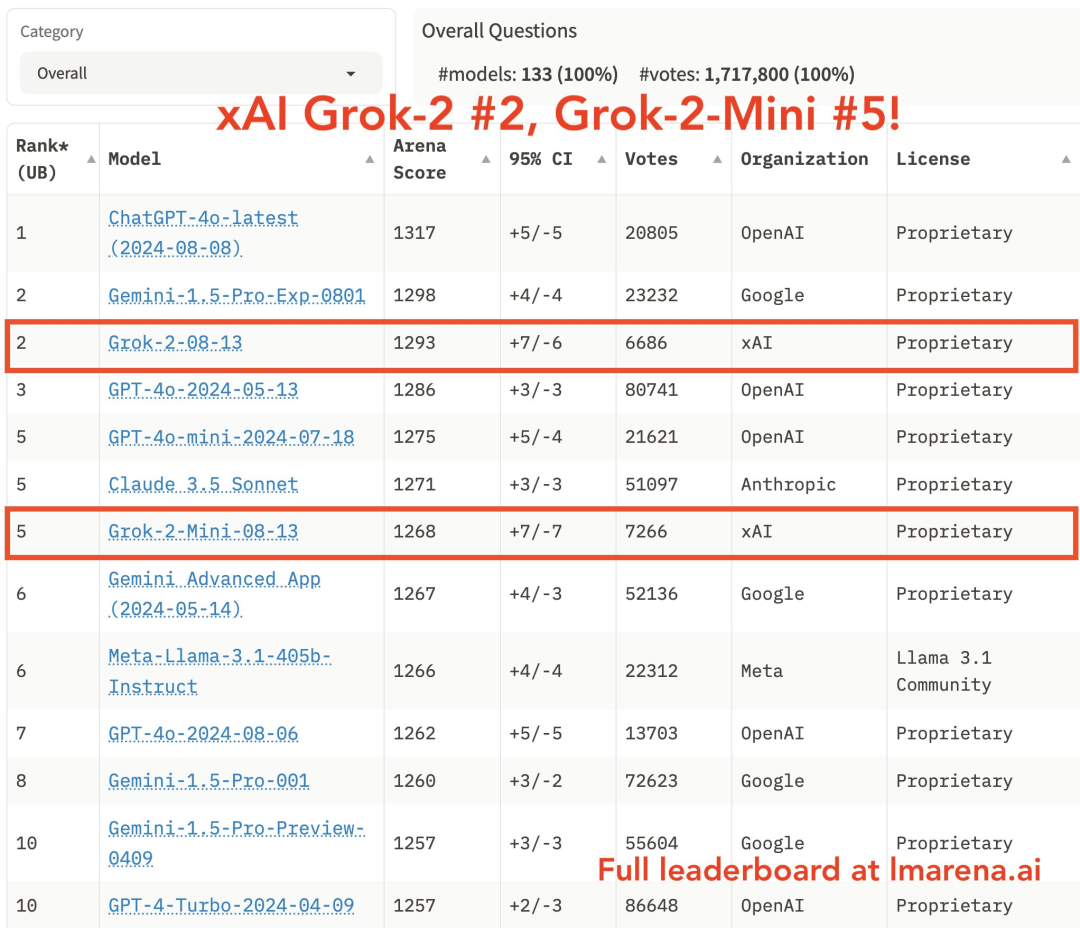 图源:https://x.com/lmsysorg/status/1827041269534879784
图源:https://x.com/lmsysorg/status/1827041269534879784Grok-2-mini 也受益于这次改进,排名上升到第 5 位,从 7266 票中获得了 1268 分的 Arena 分数,仅次于 GPT-4o mini 和 Claude 3.5 Sonnet。
努力没有白费,老板马斯克发来表扬:

根据 Babuschkin 在 X 上的回复,与完整的 Grok-2 模型相比,使用 Grok-2-mini 的主要优势在于速度更快。

Babuschkin 还承诺,xAI 会进一步提高 Grok-2-mini 的处理速度,这将使其成为寻求高性能、低计算开销的用户更有吸引力的选择。同时透露了一些关于 API 的消息:

当然,这让人们有些好奇,SGLang 为什么如此「效果显著」?
今年初,SGLang 刚刚诞生的时候,机器之心曾进行过报道。具体来说,这是一种用于执行复杂的语言模型程序的开源(Apache 2.0 授权)高效系统。SGLang 能够增强与 LLM 的交互,通过联合设计后端运行时系统和前端语言,使 LLM 更快、更可控。
SGLang 由加州大学伯克利分校、加州大学圣地亚哥分校以及卡内基梅隆大学的研究人员开发。
SGLang 目前支持 Llama、Mistral 和 LLaVA 等多种模型,兼容 OpenAI 的 GPT-4 等基于 API 的开放式模型。SGLang 能够在单个程序中通过自动缓存重用和并行来优化执行,这使它成为开发人员处理大规模语言模型的强大工具。
7 月底,团队还推出了全新的 SGLang Runtime v0.2。这是一个用于 LLM 和 VLM 的通用服务引擎。在运行 Llama 3.1 405B 时,它的吞吐量和延迟表现都优于 vLLM 和 TensorRT-LLM。在某些情况下(运行 Llama 系列模型),它的吞吐量甚至能达到 TensorRT-LLM 的 2.1 倍,vLLm 的 3.8 倍。

 伊隆-马斯克推理
伊隆-马斯克推理 

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻 拓展阅读



热门文章
- 俄航天局局长:美国正研究将俄罗斯排除出GPS卫星导航系统
2022-04-06 11:11 - 新作来了!《自杀小队:战胜正义联盟》开放世界游戏“大都会”
2023-11-17 03:19 - DOMO化学发布最新可持续发展报告认证其尼龙材料在脱碳化工与塑料行业中的关键角色
2024-06-22 03:36 - 2K直屏+骁龙8 Gen4!iQOO 13前瞻:直屏党的梦中神机
2024-06-14 03:32 - 你的独家健身搭档:雀巢绝对深黑咖啡30条28.9元到手
2024-06-22 03:46 - 星图数据:2024年618全网销售数据解读报告
2024-06-22 03:29
推荐阅读
